

Generative AI: Opportunities and Challenges for Startups
As we discussed in our previous post, the sudden rise of generative AI came from years of research breakthroughs in machine learning, particularly in transformer-based models and the Large Language Models (LLMs) they enable. Nowadays, it feels like there’s a new breakthrough every day.
One of the most significant model advancements is the release of GPT-4, which delivers several improvements over previous GPT models. These improvements include ‘human-level performance’ in a range of standardized tests, such as the Law School Admission Test in which GPT-4 scored in the 88th percentile (that is, better than 88% of humans taking the test). In addition, the new model now supports multi-modal models, enabling it to work with different types of input and output. Plainly, it can take an image as input and generate a text description of the image (Midjourney is a popular example).
With its capacity to create personalized and new content in seconds, startups and incumbents are rolling out new capabilities based on generative AI. Applications for generative AI are as diverse as generative AI-enabled web browser assistants, syllabus creators and personalized tutors, automated document discovery and more. For example, Microsoft announced that it would integrate Copilot into its Office 365 Suite and launched a Copilot just for cybersecurity, while Google announced new generative AI tools for its workspace applications, including Sheets and Docs. The generative AI race isn’t slowing down, as Adobe, Nvidia, Zapier and many others have announced new or updated products that seek to utilize or enable generative AI.
For background on how generative AI works and how we got to this point, read our blog here.
With APIs and open-source models for generative AI sprouting up, relatively easy access to state-of-the-art AI means, in our view, that having AI capabilities in products or services are quickly becoming table stakes. While we believe that software incumbents will have some advantage in building products with generative AI (in particular due to data moats), as we see it, the disruption generative AI brings will have a wide impact on all industries and professions, regardless of their size and scale. Knowing what challenges and opportunities are coming is important no matter the business’s stage.
In this blog, we’ll cover our views on some of the challenges generative AI presents, including high infrastructure costs, data privacy and model integrity. We’ll also share our thoughts on potential opportunities, including how companies can fine-tune the data they have to create niche data moats and customer experiences. Our perspective comes from several years of supporting our customers as they optimize their businesses with transformer-based large language models and our experience in artificial intelligence and conversational interfaces.
Challenge 1: Rate of change and ease of access will make generative AI easier for anyone to use
To keep up with the rapid pace of generative AI model developments, we believe that SaaS companies should seek opportunities to “stand on the shoulders of AI giants”. In other words, in our view, firms should prioritize near-term experiments with state-of-the-art foundation models developed by major players in the space, including OpenAI, Hugging Face, Anthropic, Stability.ai, Cohere, Google, Meta and others.
Over the longer term, we believe that self-hosted, open-source generative AI models will play an increasingly important role, especially for companies seeking more control over the data privacy and security of their models. However, at least in the near term, firms that use the model advancements on a proprietary pay-as-you-go basis, such as OpenAI’s GPT models, will likely have an experimentation advantage as these technologies develop.
Further, by working with hosted models, startups can focus on how to adapt generative AI to their particular use cases rather than on building and managing infrastructure. Companies can prioritize critical tasks such as “fine-tuning” models with unique data, then engineering these new capabilities into wider business workflows.
Once up and running, startups can collect input/output data and feedback from users that can further fine-tune hosted models. Then, as model innovations make their way into open-source models, generative AI models can be brought “in-house”. In time, startups may also choose to train new models from scratch. Tuning and maintenance of these models will likely become easier as more commercial or open-source model management and optimization tools become available.
Read more: Getting started with Generative AI: 4 ways to customize your models
Such “Layer 2” solutions can be considered a layer above a foundational model, making it easy for startups to train, fine-tune, optimize and secure their own models. This approach gives companies more options when they’re deciding between a fully-managed generative AI API, managing their own generative AI infrastructure or a hybrid approach.
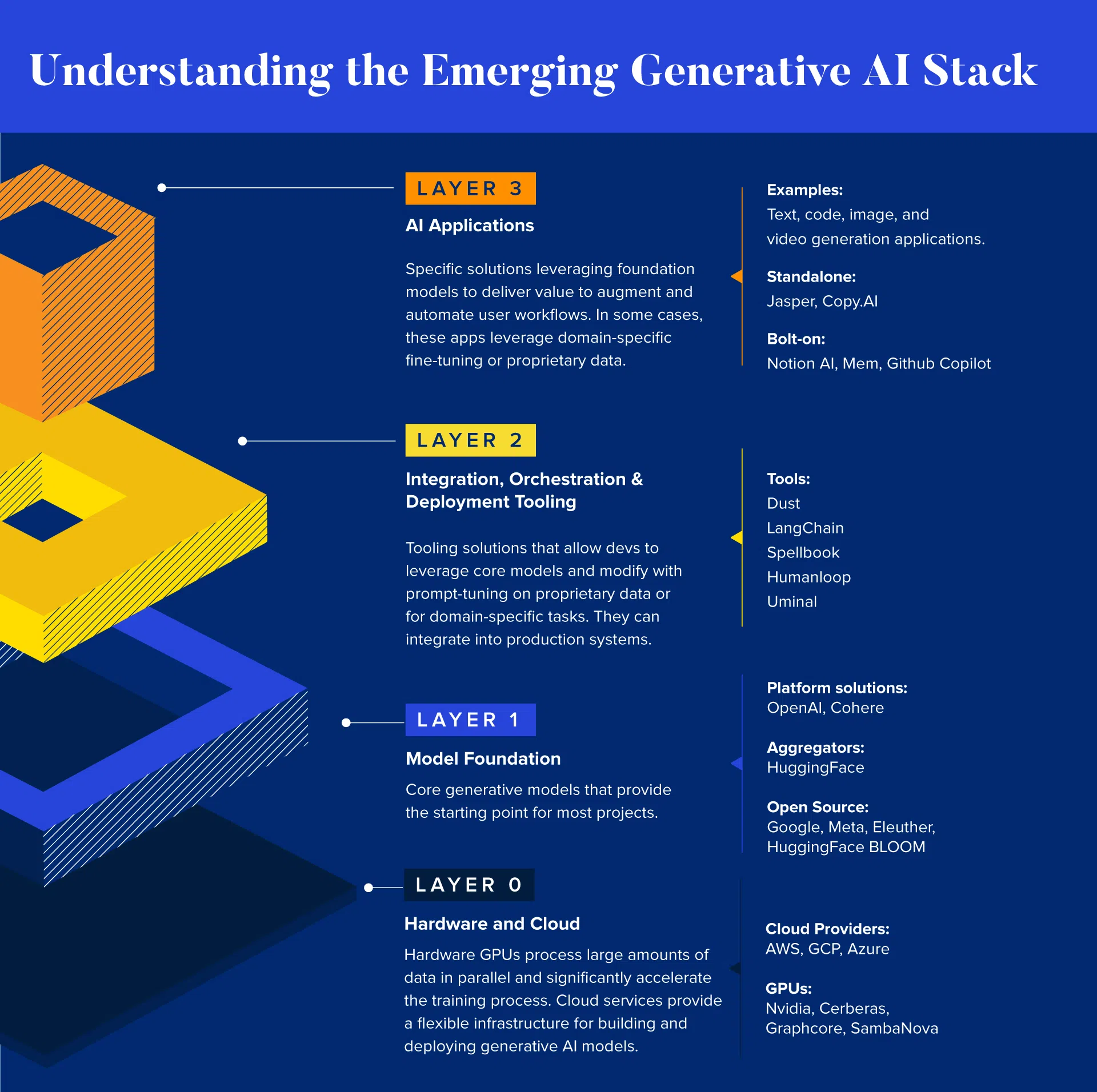
Access to generative AI technology is becoming easier through Cloud APIs, open-source models and supporting platforms. As a result, we believe it will get easier to access the technology and even self-manage models for more control. In the future, however, if companies broadly adopt generative AI, it may no longer be a differentiator.
Currently, many startups building with generative models are differentiating themselves through a combination of two things:
1. Foundation model fine-tuning — taking an already-trained model and making it more relevant to a specific task or domain.
2. Building a user experience layer that makes the technology more widely accessible and usable (ex. ChatGPT’s ability to do tasks through chat utilizing the underlying GPT-4 model).
However, we think generative AI-driven companies will need to differentiate themselves beyond using basic third-party foundation models. This need is because incumbent companies, i.e., those companies with existing software businesses and customer data, are also starting to integrate foundation models into their existing platforms and products. The implication for new startups that don’t have the benefit of incumbency, and the customer data that comes with it, is that simply integrating foundation models won’t be enough.
In the end, we think every company, incumbent and net new startups alike, will need to consider building and maintaining a defensible data moat distinguished from the underlying foundation model’s training data.
Opportunity 1: Finding differentiation through niche data moats
From our perspective, companies with defensible data moats can establish a sustainable competitive advantage — but only if these companies use data effectively by fine-tuning their models.
Specialized data can train more accurate and effective models that address specific customer needs. However, such data moats are hard to replicate and can lead to sustainable product differentiation over time. For example, say a startup focuses on collecting and analyzing customer data in retail. They may have niche data reflecting customer behavior in that specific market and can fine-tune a generative model to predict future consumer trends, outperforming generic models.
We believe incumbents with niche data moats will likely have some advantage over startups trying to incorporate generative AI for the same use case. Startups without incumbent data moats competing with incumbents with such data could bootstrap their initial data set by using AI-generated synthetic data. Once they arrive at their initial data set, they may be able to beat incumbents by operationalizing their moat rather than the depth of their moat (more on that below).
Having a lot of data can be expensive to host and analyze, but startups can work with the minimum data needed to create a satisfactory customer experience. In other words, they could refine their extraction methods to focus on quality over quantity and save resources.
Here are some examples of how to operationalize niche data moats:
Hyper-personalizing experiences for users
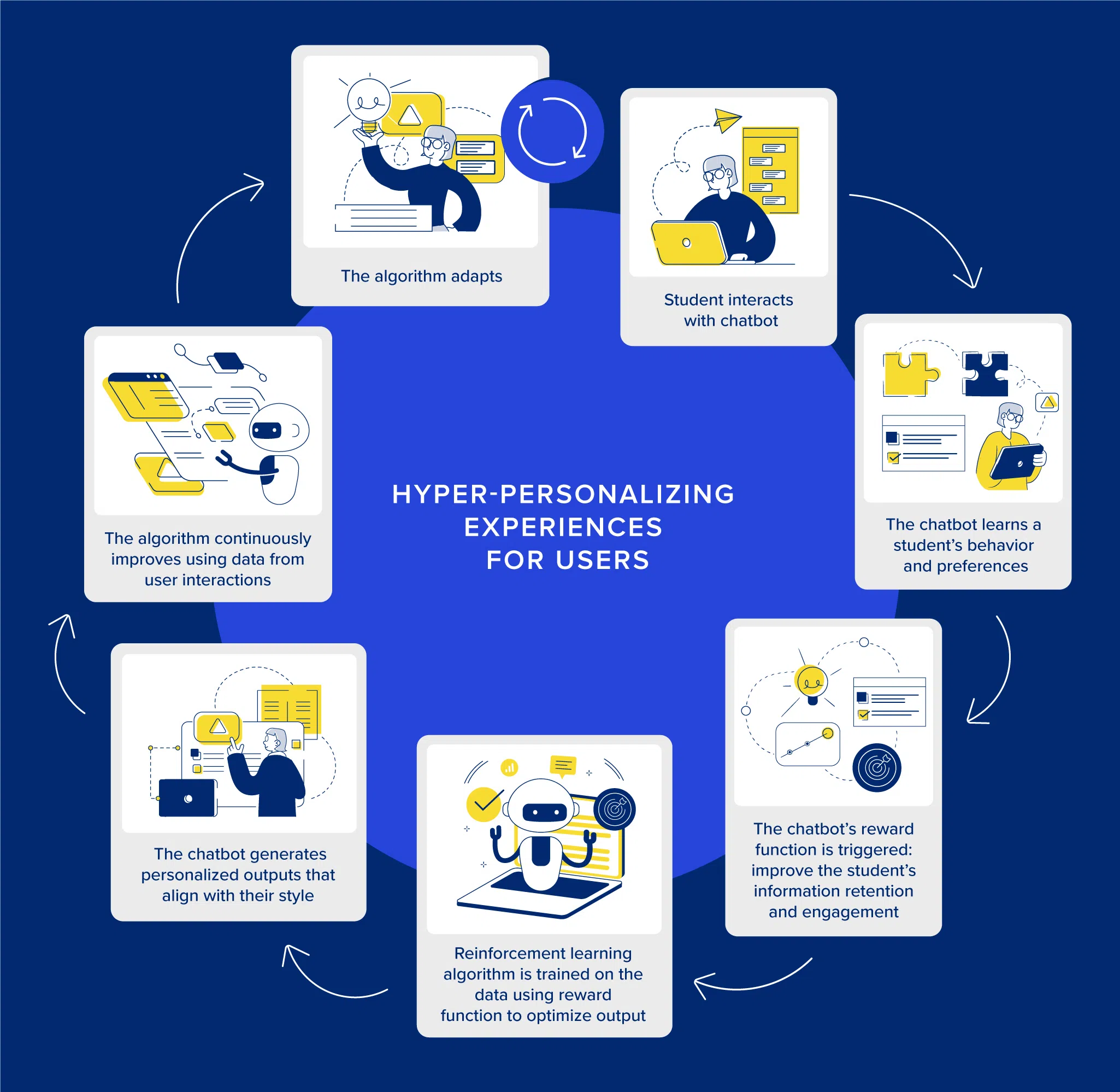
Fine-tuning with segmented user data allows models to generate personalized outputs for groups of people who share similar preferences. Differentiated companies will go further than this, creating hyper-personalized experiences unique to each user. One approach to designing hyper-personalized experiences is using reinforcement learning to fine-tune a language model.
For example, a personal tutor chatbot could help university students in a personalized way. In this scenario, the company collects student behavior and preferences data while they’re interacting with a general chatbot. Next, a reward function reflects the chatbot’s goals: improving the student’s information retention and engagement. The reinforcement learning algorithm is trained on the data using the reward function to optimize output. The chatbot is then deployed, generating personalized outputs that align with an individual student’s learning style. Finally, the algorithm is continuously improved using data from user interactions, adapting to the student’s changing needs.
Reinforcement Learning (RL) is a vital machine learning technique to make hyper-personalization work. In RL, a model (or RL agent) learns through interactions with its environment. As the RL agent takes action, its environment is impacted; the environment transitions to a new state and returns a reward. Rewards act as feedback signals to the RL agent to tune its action policy, with the RL agent adjusting its policy throughout the training period so that its actions maximize its reward. Human Feedback (HF) can be used to inform the reward model, with human annotators ranking or scoring model output. This interaction could look like upvote or downvote buttons on a model interface.
Combining these two techniques, known as Reinforcement Learning with Human Feedback (RLHF) can improve language models by aligning them with human values that are not easily quantifiable (e.g., being funny, helpful). RLHF can help models avoid erroneous answers, reducing bias and hallucinations. These models may also be more efficient; for example, OpenAI found that their 1.3B-parameter RLHF model outperformed their 175B-parameter non-RLHF model, despite having over 100x fewer parameters.
However, RLHF is not a perfect solution. Manual training is costly, and collecting human feedback in a clean and standardized way is difficult and time-consuming. And, no reward model can conform to the preferences and norms of all members of society. Therefore, it’s necessary to take measures to save costs, like freezing layers and only training part of the model. Model drift is another concern that engineers must try to prevent; for example, the model may find shortcuts to maximize reward while violating grammar and social norms. An example of where an RL model was led astray via interaction with human users was Microsoft’s Tay chatbot. Released in 2016, Twitter users corrupted Tay in less than 24 hours.
For more specific steps on RLHF, check out our blog post on getting started with generative AI models.
Challenge 2: Maintaining infrastructure is expensive and time-consuming
While many firms will use third-party models such as OpenAI’s GPT-4, we believe many innovators will integrate self-hosted models directly into their products. The reasons for doing so will vary, but from our perspective, the reasons often relate to the ongoing cost of API access to generative AI services and data security and privacy concerns with third-party hosted models.
When companies choose to manage their own models, they typically encounter challenges at the infrastructure level. Generative AI models require significant computational and memory resources to run and demand regular maintenance and updates. In addition, these models may create new cybersecurity risks (more on this below).
As generative AI use grows within an organization, scaling models to accommodate increased demand will consume further resources — a big hurdle for resource-strapped startups compared to incumbents. While incumbents can spend more on cloud processing, employees and software infrastructure to host models, startups may be limited in how much data they have, creating a ceiling for model quality.
Opportunity 2: Get your models to work smart, not hard with LLM Ops
There is a significant opportunity for emerging Large Language Model Ops (LLM Ops) providers to support companies as they integrate generative AI into existing systems.
Companies that can optimize costs and make stages in the ML lifecycle easier to understand and build can help generative AI startups scale over time.
For example, startups may not need the biggest model to complete a task. They may only need a few million parameters rather than a few hundred million parameters, to get the desired level of accuracy for a particular use case. MLOps tooling can help businesses define what size and configuration of model is “good enough” for their desired processes. Despite the continued focus on bigger models with even more parameters, it has been our experience to date that a key task when bringing LLMs into production is to make them smaller.
We’ve seen this in action with one of our former customers, where we supported a project to implement speech-to-text transcription, helping the company adopt a bespoke speech recognition model (called Wav2vec). Wav2vec contained 300 million parameters and inference latency, making high hosting costs a bottleneck to production. We helped the firm to use model compression to make these models two times faster and more than four times smaller than the original model.
LLM Ops providers can identify ways to optimize model size and training processes, as LLM training is expensive. For example, OpenAI has reportedly spent up to $12 million on a single training run for GPT-3. The scale of costs involved can result in cost-accuracy tradeoffs and under-optimized models. Over the last few years, models have grown bigger and bigger; OpenAI GPT-3 was 10x the size of its predecessor, GPT-2. However, in April 2022, DeepMind Chinchilla became the second highest-performing LLM on the market at only 70 billion parameters, surpassing GPT-3, Gopher and MT-NLG. Chinchilla had fewer parameters but was trained on more data than GPT-3, demonstrating that many current LLMs are likely undertrained and oversized.
There is also room for innovation at the hardware level. For example, one approach to training LLMs with hardware using modern GPUs is model parallelism, where language models are split over multiple GPUs and each GPU stores one or more layers. While advances like model parallelism have improved training speed and cost, they have limitations — leaving a gap that startups could try to fill. For example, startups may be able to create optimized versions of a particular model that can run efficiently on cheaper hardware.
Challenge 3: User experience design won’t be the same again
ChatGPT has pushed the boundaries of natural language for human-computer interaction. Anyone who has used ChatGPT has likely had that “ah ha” moment of creativity after chatting with a computer and getting back coherent answers.
We believe that Conversational AI, an area we’ve tracked over the last several years, has now arrived thanks to the combination of LLMs and RLHF reflected in ChatGPT.
As we see it, it’s likely that traditional user experience (UX) design won’t be the same again. Traditional UX design requires designing smooth interactions between users and websites, mobile applications and software. It involves in-depth user research and consistent testing to ensure the user journey makes sense. However, conversational interfaces, which can provide personalized answers to users based on their own unique way of speaking, could change what we consider traditional UX.
This shift may challenge incumbent software providers with large investments in user interface software, and the associated skills to build such software. Many software packages have an extensive investment in the screens that help users navigate and access the underlying functionality of the software program. With conversational interfaces that can achieve the same outcomes with natural language prompts instead of complex screens, firms embracing conversational AI will likely have an advantage.
Opportunity 3: Embrace conversational interfaces in your workflow
As much as Conversational AI represents challenges to incumbent firms that have invested in traditional UX rather than chatbots, we think conversational interfaces are something firms can embrace.
Traditional UX design will remain important, but we believe that conversational interface capabilities will provide a competitive advantage.
With conversational interfaces, UX designers can design user workflows — the actions users take to meet a goal within an app — much faster. This improvement happens because once a conversational AI interface is available, expressing tasks as a combination of natural language ‘prompts’ mapped to key services to provide ‘actions’ may prove much simpler than creating traditional workflows and their associated screens. OpenAI’s newly announced “ChatGPT Plugins” and the new Natural Language Actions from Zapier are examples of how the next wave of chatbots may be able to take real action on behalf of businesses.
If companies do need to build more traditional software interfaces, they may be able to use generative AI to produce these user interfaces quickly. In fact, in what might be a glimpse into the near future of UX development, during the GPT-4 launch in March 2023, OpenAI demonstrated the model creating a functional website landing page based only on a paper sketch of the page and a text prompt asking for the website to be written in JavaScript.
Challenge 4: Privacy & trust in generative AI models is not guaranteed
It’s important to remember that generative AI models, no matter the source, are highly likely to reflect any bias or inaccuracies of the data they’re trained on.
While Generative AI models aim to create unique, diverse content, they tend to replicate the data they were trained on (and in some cases, create inaccurate or false information with confidence).
Many open questions exist about the legality and ethics of model training methods core to generative AI’s success. Court cases in progress (like in the case of Microsoft’s Copilot) are exploring whether models trained in art, text and code violate the copyrights of artists and developers. Many experts have also raised concerns about how AI can cause or exacerbate societal inequities. For example, OpenAI paid Kenyan workers $2 an hour to read and view violent and disturbing content in an effort to make their model(s) less toxic — the content was so traumatizing to workers that Sama, the agency contracting workers to OpenAI, canceled the contract earlier than planned. We expect these issues to play out over the next few months and years.
Because of these ongoing debates on ethics in generative AI, companies should consider these issues in their strategy as they experiment with generative AI models. In addition, companies should put trust at the core of what they do and how they design their products. In our Principles of Trust whitepaper, we provide guidelines on how companies can score themselves on trust and practical ways to build a foundation of trust.
As Alex Manea, Georgian’s Head of Privacy and Security, puts it, “It reminds me of the early days of the internet — both in terms of how it could revolutionize how we live, but also the potential to cause harm if we don’t put in the right guardrails.”
Here, we explore these emerging trust-related challenges in more detail.
Establishing data usage rights
The developers of Copilot, Microsoft, GitHub and OpenAI are confronting the implications of using internet data as training data. They face a class action lawsuit that accuses them of violating copyright law. Copilot was trained on billions of lines of code found in public repositories on GitHub and the lawsuit alleges that many of these repositories have licenses that require attribution, which at the time of writing wasn’t provided by Copilot. Similarly, Midjourney and Stability AI are being sued for scraping millions of images from the web — without artist consent — to train their models.
These cases raise several legal, ethical and privacy considerations. Businesses may be tempted to use aggregate customer data to train models for greater accuracy and personalization. However, we believe that the legal, ethical and privacy implications should be considered concerning the user experience.
Other firms, such as Cerebras Systems, are taking a deliberately open approach, sharing detailed information on how models were trained, enabling greater transparency into how a model works. For its part, Adobe has claimed that the model their new image generator uses was trained only on images that they had the right to use.
What’s more, there is an ongoing discussion about whether art or copy generated solely by AI can be copyrighted. The U.S. Copyright Office recently rejected an application to copyright an AI image as it “lacks the human authorship necessary to support a copyright claim.”
Using AI to deceive
Generative AI may present several opportunities for bad actors. For example, users are already generating human-quality essays and passing them off as their own work. At the same time, there are some projects attempting to create tools that detect AI writing and catch students passing off fully AI-generated work as their own, including one from a Princeton student and one from OpenAI itself.
Generative AI can also be used to create large quantities of human-sounding misinformation, which can spread through existing social media channels. Human-sounding misinformation happens partly because LLMs are not trying to understand how the world works but trying to mimic humans. While individual providers may implement guardrails to protect against misinformation, the availability of open-source models makes this a particularly tough challenge to address.
Another emerging issue is the ability to generate convincing “deep fakes” splicing together people’s appearance, mannerisms, voice, speech patterns etc. A recent example of deep fakes was the use of new text-to-speech technology from startup ElevenLabs to create deep fakes of celebrities saying offensive messages. The company has since made changes to how users need to register to use the service.
New privacy and security concerns
In our opinion, another potential issue with tools such as ChatGPT is that users may enter confidential data in prompts. Currently, models generally aren’t clear about how that data is stored, handled and processed. For its part, OpenAI allows users to opt out of having their ChatGPT prompts retained by OpenAI for training purposes.
Another emerging issue is that software developers may add vulnerabilities to the code they are developing when relying on generative AI too much. For example, a recent study explored the implications of using AI-code generators on code security. The study found that developers using the Codex AI model (on which GitHub CoPilot is based) to generate security-related code were more likely than the control group to generate code with security issues. At the same time, the group using the Codex AI model was more likely to believe that its code was secure compared with developers writing their own code in the control group. A related issue is that hackers can use tools to quickly find vulnerabilities in source code (this scenario has been demonstrated with ChatGPT). And as we mentioned earlier in the context of RLHF, attackers may intentionally manipulate models with bad data in order to change tool behavior/outputs such as in the case of Microsoft Tay.
Where companies host models in their own cloud environment, they can have greater control over the use and security of the data themselves. However, as models get larger as with LLMs, more firms are relying on APIs from larger players like OpenAI, which means the data hosting is handled by OpenAI itself. This situation makes it harder for companies to assure customers of the security of the customers’ data, as the companies have to rely on cloud hosts.
Opportunity 4: Create new value through trust
While these trust-related challenges are complex and will take time to address, we believe that taking a thoughtful approach to issues such as privacy, security and fairness in generative AI-enabled solutions will be a key opportunity for differentiation.
We believe that the opportunity to create new value through trust is significant. If companies can create a trusted user experience, they will potentially get a direct, unfiltered view into the voice of the customer through their prompt data. We believe that collecting this data can provide deeper and richer insights into how to create additional value for customers and create more opportunities to enrich this data. However, companies must earn the right to get that data by proactively addressing trust-related concerns.
Our own Principles of Trust provide a framework for identifying opportunities to earn customers’ trust.
Remain true to the stated purpose and values
We believe that an early consideration in generative AI adoption should be how a solution aligns with a company’s stated purpose and how generative AI adoption may generate additional value for a firm’s customers. For example, a generative AI solution that could potentially generate biased responses would be self-defeating to a company that champions diversity, inclusion, belonging and equity.
We see the ethical implications of generative AI as complex, and it may change frequently as the underlying technology advances. In our experience, one way to ensure a firm holds itself accountable to its purpose and values is to establish multi-disciplinary teams to consider AI safety and trust questions. Some companies, OpenAI included, publish the principles that guide their use of AI to increase accountability.
Set a high bar for reliability
Over the past few years, AI product users have become accustomed to the fact that its recommendations and predictions are based on probability. A confidence score or explanation often accompanies a recommendation to help users contextualize it.
To date, ChatGPT provides a disclaimer that it may hallucinate but has no feature allowing users to see sources or assess the confidence of a given response. ChatGPT gives responses confidently regardless of whether they are true or not. Similarly, Bing was reported to have asked users to apologize for questioning its untrue responses in the past.
It may be that startups, especially B2B companies, will be held to a higher standard if they embed generative AI functionality, that is relied upon by their customers, into their products. From our perspective, reliability will be a key differentiator, and companies that prioritize reliability by explaining answers, admitting uncertainty, and using other effective approaches, will gain user trust.
Communicate decisions openly and often
There are a lot of open questions about misinformation, ethical use of intellectual property and security and privacy in generative AI. To address concerns, we think that companies can be proactive in their communications around how they use generative AI in terms that are clear and easy for users to understand. To ensure clear communication, a company’s users should easily understand the company’s approach to privacy and security, being transparent about what third-party services are being used and where data is going and why.
We believe another important way to earn trust is to establish in the interface itself what a company’s solution is, what its tool is capable of doing and why it was designed that way. If there are specific regulatory reasons or security concerns that can be addressed proactively, this disclosure would be a good place to do so. For example, a company may explain up front what kind of personal information it will or won’t ask for during a conversation, what happens to data shared by users and the rationale for given responses.
Security and privacy first
Security and privacy remain fundamental to earning trust, regardless of the underlying technology. While many new generative AI companies are following a product-led growth model — where consumers adopting the product do not necessarily ask too many questions about security and privacy — we think that these companies will need to demonstrate enterprise-level protection to convert individual accounts to larger corporate deals. Conversely, incumbents, which are adding generative AI to their solutions, may be able to leverage their existing security and privacy postures as a differentiator.
We think there are also specific opportunities to take a security and privacy-first approach with generative AI. Companies may, for example, take additional steps to protect user privacy, including anonymizing information that is or will be shared with generative AI services. In addition, to protect user privacy, companies can remove any identifying information to help disassociate the ‘prompt’ being sent to the service from particular users or individuals. It may also be possible to enhance a company’s own security by leveraging generative AI tools to analyze its own source code and look for common security vulnerabilities and better ways to harden its code.
Tracking generative AI development
We believe the emergence of generative AI presents critical opportunities and challenges for startups and incumbent businesses alike. In our opinion, companies can create more advanced and sophisticated AI products with fewer development resources.
To maintain competitive advantage, those applications must be highly personalized and must learn and improve over time. In the face of incumbents with more resources to spend on larger models and infrastructure, startups will likely need to find creative ways to be differentiated. To be creative, startups should consider the size of models needed for a task to create the optimal experience for customers. For both startups and incumbents, it will be important to be proactive about trust, especially as people trust generative AI models with their sensitive data and generative AI becomes a core part of business processes.
At Georgian, the interconnections between trust and artificial intelligence in technology are something we track. From our perspective, a company can build the highest-performing model in the market. Still, without consideration for consumer privacy, ethics and data quality, the model would be unsustainable over time without the trust of the company’s users and an assurance of reliability.
Over the next few months, we’ll share our thoughts on what trust means in generative AI, the new markets that generative AI can create and more.
Read more like this
KumoVC: Turning Venture Data into Instant Predictions with KumoRFM
Originally published on Kumo.ai’s blog. In this technical blog post, Azin and…
Verticalized Voice AI – The Next Application Layer Shift
Every decade or so, a new interface reshapes not just how people…
From Static to Adaptive: Scaling AI Reasoning Without the Waste
2025 has been the year of reasoning models. OpenAI released o1 and...