
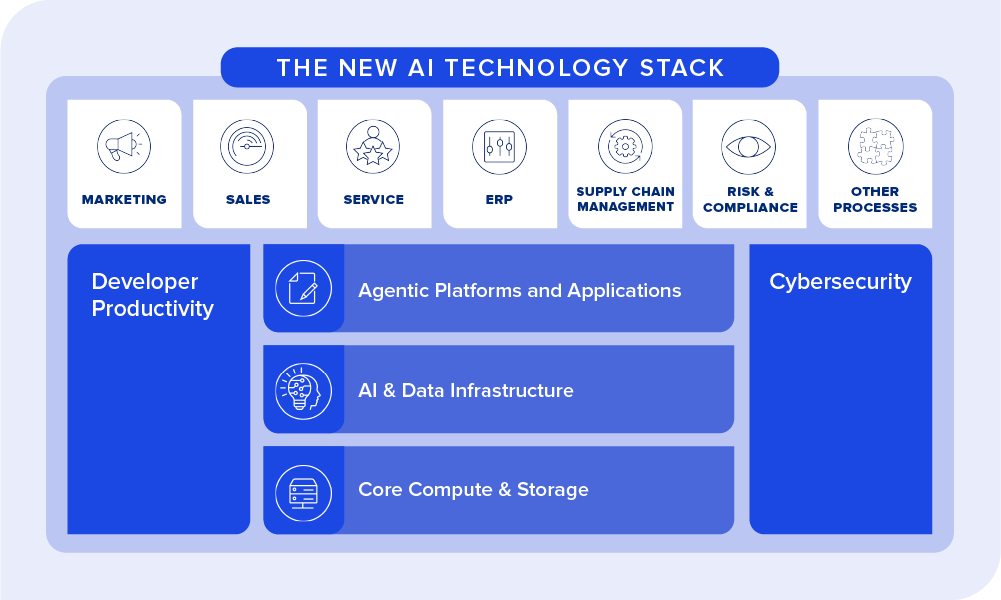
Agentic AI Infrastructure
This paper explores the agentic and AI infrastructure layer that is being built to help agentic systems reach enterprise scale and reliability.





AI Landscape Series
Agentic AI Infrastructure
This paper explores the agentic and AI infrastructure layer that is being built to help agentic systems reach enterprise scale and reliability.
Agentic Platforms and Applications
This paper explores the technical foundations of AI agents, their potential impact on traditional software and business models and how the software industry is evolving in response.
More insights from the blog
Why Georgian Invested in Replit
We are excited to announce our latest investment in Replit’s $250 million…
Georgian Releases 2025 AI Adoption Enterprise & Growth-Stage Benchmarks
Compiled in partnership with NewtonX, and leveraging 600+ exec respondents, the report…
A Practical Guide to Reducing Latency and Costs in Agentic AI Applications
Scaling companies that are actively integrating Large Language Models (LLMs) into their…
How to Build Differentiated Agentic AI Products: A Practical Guide
In her latest blog, Asna Shafiq dives into: Identifying potential use cases for agentic AI, starting small to build confidence and tips to differentiate your AI solution.
Why Georgian Invested in Ambience Healthcare
We are pleased to announce Georgian’s participation in Ambience Healthcare’s $243 million…
Data Security in the Age of Agentic AI
AI now lies at the heart of the battle between attackers and defenders, potentially reshaping the dynamics of cybersecurity. While malicious actors exploit AI to identify vulnerabilities and craft sophisticated attacks, security teams are increasingly relying on AI to detect and neutralize threats. In my view, this dichotomy underscores the need to balance innovation with responsible safeguards.
Georgian Purpose Report 2024
This reporting period marked five years since the establishment of Georgian’s Environmental, Social, and Governance (ESG) program. Over this period, we have sought to identify and apply standards that are relevant to our industry, and to explore ways to consider this guidance within our investment processes and operations.
How Vibe Coding is Changing the Economics of Software Development
Software development has changed dramatically in recent years. Developers have moved from copying code from Stack Overflow to using ChatGPT for code suggestions, using Integrated Development Environments (IDEs) with AI-powered autocompletion, to now prompting large language models (LLMs) to generate entire applications. This shift is transforming how engineering teams work and is reshaping the economics of software creation and cybersecurity.
Only 7% of Surveyed Canadian Tech Leaders Believe That They Have Reached Advanced AI Maturity, New Report from Georgian Finds
Georgian & NewtonX’s global AI study of 634 executives suggests that Canada is trailing…