

Four machine learning techniques in simple terms
Often when you hear experts talk about machine learning and artificial intelligence, it’s easy to feel alienated. A common sentiment we hear from entrepreneurs is that it can be hard to get beyond the buzzwords and grasp the specifics of what ML and AI can actually accomplish.
At Georgian, we’re fortunate to work closely with our portfolio companies to implement many different flavors of ML and AI. We also talk to hundreds of companies every year that are just getting started making their first data science hires. From all of these conversations, we benefit from pattern recognition that helps us recommend techniques to explore.
In this post, our aim is to go a few layers deeper than the overarching terms of ML and AI. We will examine four core business problems that we see many B2B SaaS companies face as they adopt these technologies, share some relatable examples and provide an overview of some impactful techniques that you can consider applying to your business.
These business problems are:
- Lack of Training Data
- Complex Decision Making with Scarce Resources
- Personally Identifiable Information Privacy Concerns
- Difficulty Explaining a Product’s Output or Recommendation
If any of these issues resonate with you, read on to learn more.
1. Lack of Training Data
Creating value as a B2B SaaS company is often highly dependent on creating a rich and personalized experience for each customer. Personalizing the user experience is one common application of ML. Unfortunately, getting a model to a point where it provides useful personalization for new customers is easier said than done. To take advantage of ML from day one, you need to be able to train your model with high-quality data.
When getting started with machine learning, many B2B companies find themselves with less training data—the data used to train a model—than they need. This is because the number of data points collected for B2B companies is typically much more limited than in a B2C context, due to the smaller and more focused user base.
Let’s take a look at two key challenges that stem from a lack of training data: The Cold Start Problem and Poor Performing Models.
The cold-start problem
Imagine you are moving into a new apartment, and you want to get settled quickly. Would you rather have a blank space with no furniture or a pre-decorated space with furniture suited to your taste?
This is a simple way of visualizing the cold start problem. If you want to onboard a new customer and provide them with a meaningful and personalized experience, collecting the data you need can take several months, and customers don’t want to wait that long. Many B2B SaaS companies struggle to move from a “blank space” user experience to a personalized user experience that improves over time through machine learning. Not providing value quickly enough can hurt user adoption, significantly impact revenue retention and limit up-sell opportunities.
Poor performing models
Even after long periods of data collection, it is possible that you still won’t have enough to make a positive impact. The performance of machine learning models relies heavily on the volume and quality of training data. Without the right fuel, you are at risk of your models running at half speed.
In situations where the output of your model is mission-critical, a poor-performing model can have serious consequences. Let’s look at two products and the impact of a false positive – the first is a cybersecurity threat detection system (B2B), and the second is a music recommender (B2C). If you aren’t a fan of rap music but you get a Drake song recommended, safe to say you can easily skip it with no consequence. If a cybersecurity system incorrectly recommends you shut down your website due to suspicious activity, that could cost you millions in lost sales and person-hours.
Whether you recommend music or detect threats, there is no denying that poor model performance will cause a user to lose trust in your product. The more they lose trust, the more likely they are to abandon your product altogether.
The solution: transfer learning
Transfer learning is the computer science equivalent of using a skill or knowledge you’ve picked up in the past and applying it to a new situation.
For example, consider a person that knows how to play tennis. This person can take many of the same skills and knowledge learned from tennis and apply it to a new racquet sport, like squash. This person will likely learn squash much faster than someone that is starting from scratch.

Transfer learning follows this logic, allowing you to leverage relevant existing information from past customers when building a machine learning model for a new customer. Take the example above – you might use the hand-eye coordination and the forehand / backhand strokes from tennis, and apply them to squash. But court positioning? Not so much.
Transfer learning can significantly reduce the amount of time it takes to train the new model, easing the pain of the cold start problem. The model may also perform better because it uses existing knowledge as a starting point and improves from there.
2. Decision Making with Scarce Resources
Machine learning models can generate powerful insights. In some instances, however, these insights need to be cross-referenced against sets of constraints that a business faces.
Let’s look at an example from a Georgian portfolio company, Ritual. Ritual is an order-ahead app that focuses on the restaurant space. To personalize each user’s account, Ritual uses an AI model to determine what restaurants it should recommend for each user. Each restaurant, however, has limited resources and can only serve a certain number of customers during each lunch hour. Therefore, Ritual needed to find a way to optimize their recommendation model so that it did not flood restaurants at lunch, while still giving valuable recommendations to its users. Optimizing these kinds of complex decisions can take a lot of effort, and all too often, the outcome is suboptimal.

The solution: constrained optimization
Constrained optimization is a process that uses applied mathematics to tell you exactly what the optimal decision is in these difficult situations.
In constrained optimization, there are usually three components:
- Variables (i.e., restaurants to recommend)
- Constraints (i.e., the number of people each restaurant can serve at lunch)
- An Objective (i.e., how to maximize user satisfaction with recommendations)
By transforming each component into mathematical functions, you can build a model to answer the question: how do I set my variables so I can maximize my objective while staying within my constraints? How do I recommend the restaurants that will maximize user satisfaction while not overwhelming each restaurant?
In this way, constrained optimization gives you a formal way to allocate resources in a complex and dynamic setting. Using the outputs from this process, you can confidently automate your decision making, knowing you have found the optimal allocation.
3. Personally Identifiable Information (PII) Privacy Concerns
In the wake of many high-profile data breaches, users are less willing to share their data and personally identifiable information than ever before. As we have already discussed, access to customer data is vital for creating high-performing models. With this in mind, it’s no surprise that 96% of business leaders listed building and maintaining stakeholder trust as a top priority in 2020.

Anonymization of data was once the way to solve the problem of protecting private information. However, in the past few years, it has become clear that data can be de-anonymized if you know what you’re doing. In a high-profile example of de-anonymization, hackers took Massachusetts Group Insurance Commission disclosures and identified the Governor of Massachusetts’ medical records.
So if trust is paramount and data isn’t easily anonymized, where does that leave software companies that need data to thrive?
The solution: differential privacy
Machine learning scientists often use private data to train a model. Once in production, there is a risk that attackers could query the model enough times to identify personal information.
You can minimize this risk using a technique called differential privacy. This concept involves injecting noise—or random data—into your original dataset, so it’s harder to tell what is real data and what is noise. How much random data do you add? Enough that it’s virtually impossible to identify specific individuals with full certainty, but that the data is still useful from a statistical standpoint.
Using differential privacy gives you a dial that you can turn up if you’re particularly sensitive to private data loss. This is a great way to ensure that your AI product is measurably private and trustworthy.
Using differential privacy is beneficial because it not only prevents deanonymization, but it also provides SaaS companies with a tool to showcase exactly how effective their privacy techniques are. The benefits of leading with a message of trust like this one can be huge— check out IEX and Integrate.ai as two examples. Once your customers buy into the advantage of a more trustworthy approach, you will be able to lead the conversation and set buying criteria that include trust.
More to come on this in our State of Trust report 🙂
4. Difficulty Explaining Your Product’s Output or Recommendation
We often hear machine learning models called black boxes – we put data in one side and receive an output on the other, but the processes that run in between are a mystery.
For some industries, being able to explain your machine learning model is vital to ensure compliance with government regulations or mitigate negative press. A classic example of the black box problem is the recent criticism of the Apple Card in the US. Several public figures, including Apple’s co-founder, Steve Wozniak, claimed that the credit approval system showed signs of gender bias. The model approved men for higher credit limits than their female spouses, even though their assets were shared. Because Apple’s machine learning model was a black box, they were unable to explain their model’s output, leading to widespread criticism.
For other industries, shining a light inside the black box can significantly enhance the customer experience. One great example of this is Grammarly, a company that uses artificial intelligence and natural language processing to improve your writing. Rather than simply fixing your mistakes, Grammarly points out mistakes and areas for improvement. Each suggestion comes with a box that shows why it was flagged. This use of AI as an assistant to humans is a very impactful use of AI technology; however, it requires a deep knowledge of both your user’s objectives and how your model makes decisions.
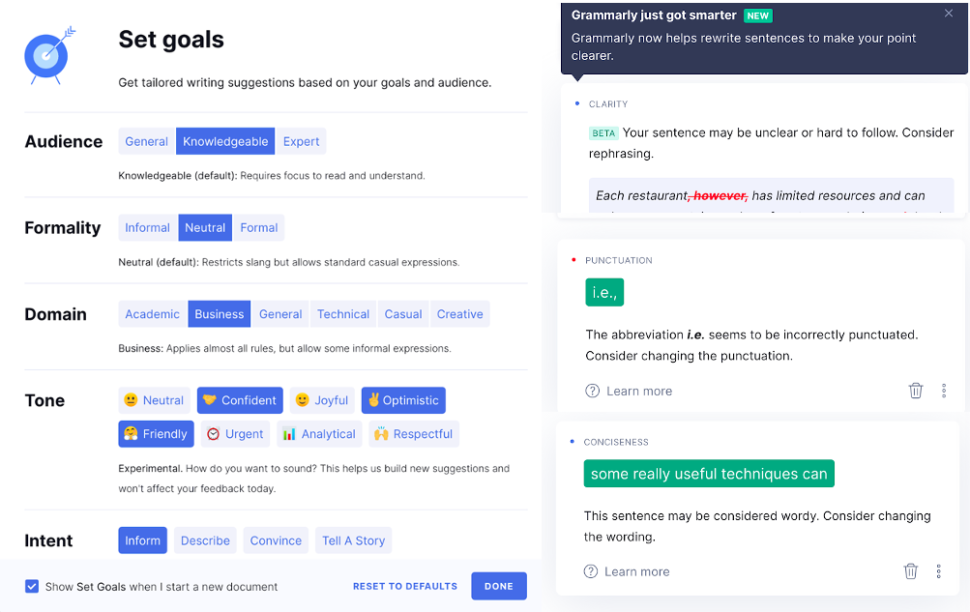
Grammarly’s product allows you to set your writing goals and then make suggestions tailored to your choices. You can accept or reject each tip as you edit your writing.
Regardless of what type of outputs your machine learning model produces, taking proactive steps to counteract the black box problem is a great strategy to maximize trust with your users. Unfortunately, this is easier said than done.
The solution: explainability
Explainability is a broad term that describes several machine learning techniques that can get inside the black box and explain your outputs.
One explainability technique that we have found to be particularly useful and scalable is the Shapley Additive Explanations (SHAP) technique.
In the SHAP technique, the reason for a specific outcome is broken down into a list of features. When assessing whether or not someone should receive a credit limit increase, relevant features might be historical credit score, existing assets, salary, and so on.
Each of these features is then assigned a SHAP value. The SHAP value tells you how much influence that particular feature had on the outcome achieved. This value can be positive or negative, depending on whether the feature made the outcome more (positive) or less (negative) likely to occur. In our credit approval example, a ‘bad’ credit score would likely have a negative SHAP value in the decision to approve a credit limit increase.
Once you have insights that explain how your model is working, you can use them to investigate any bias before releasing the product. When you’re happy with your model, you can translate your explanations into user-friendly language and find thoughtful ways to insert them into your product experience. Doing this effectively will make your users feel comfortable and help them perform your core actions with confidence.
Conclusion
We hope this was a useful overview of some common business problems we see from companies exploring AI and machine learning, and that you have a few takeaways from the techniques we outlined. If any of the problems or techniques are particularly interesting to you, please don’t hesitate to reach out to evan.lewis@georgian.io.
If you enjoyed this read, here are a few other resources you might enjoy:
Georgian’s CEO’s Guide to Trust
An Introduction to Transfer Learning
Constrained Optimization: How To Do More With Less
Georgian’s CEO’s Guide to Differential Privacy
Thanks for reading!
Read more like this
Agentic AI and the Rumors of SaaS’s Demise
Introduction: A Conversation About Big Shifts When I joined Tobias Macey on…
Why Georgian Invested in Island (Again)
Island, the developer of the Enterprise Browser, emerged from stealth in early…
Why Georgian Invested in Render
We are pleased to announce Georgian’s investment in Render’s $80M Series C…