

Agile AI at Georgian – Part 4: How Data Can Make or Break Your AI Project
Welcome back to Agile AI at Georgian, where I share lessons learned about how to adapt agile methodologies for AI products. In previous installments, we’ve talked about finding your project’s North Star, motivating your team and mastering experimental design. Today, we’re going to delve deeper into the lifeblood of any AI project: data.
No matter how strong your team and cutting-edge your algorithms, the underlying data you’re working with can make or break your AI project. The stakes are high: issues with your data can have significant downstream effects, and errors can be amplified by machine learning. Despite this, data is often not given the attention it deserves. We’ll cover how data fits into the product lifecycle and how to run a data sprint.
Before we do, let’s take a look at the two big challenges. First, many teams underestimate the complexity of finding the right data and figuring out how best to get value from it. For instance, when my team was building a model to score companies, we thought it would be relatively simple to use employee count as a feature in our model. Many data sprints later, it turns out this seemingly straightforward feature actually requires combining four distinct data sources to achieve sufficient data quality and coverage. Second, it can be challenging to figure out the best ways to apply agile methodology to data.
Tackling these challenges head-on not only will lead to a better product, but can lead to long-term differentiation and competitiveness. Taking the time to find, collect, clean and enrich the right data can give you a leg up and provide the “secret sauce” for the intelligence features of your product.
A proactive approach to data
One of the major lessons our team has learned is that it’s easy — but costly — to underestimate the value of data testing. As you get further into the product development process, the cost of an unchecked data error grows exponentially. Ideally, you want to test the data at every handoff or transformation to ensure it matches your expectations and stop it from poisoning downstream datasets and models.
We’ve also learned the value of investing in data skills in our team. Data infrastructure, data operations, data analysis and mapping business requirements to signals and specific data sets are all distinct needs that benefit from specialization. Over time, our team has gotten better at identifying data issues and anticipating their potential downstream impact.
Throughout the process, it’s also crucial to keep your North Star in mind. Make the best of the data you have available — but make sure that in doing so, you are staying true to the business purpose of the product.
Understand the data lifecycle
One of the main misconceptions that can hamper teams starting out in AI is the idea that preparing data is a one-time step in the process. Instead, data management is better viewed as an ongoing lifecycle that intersects with the product lifecycle at key stages.
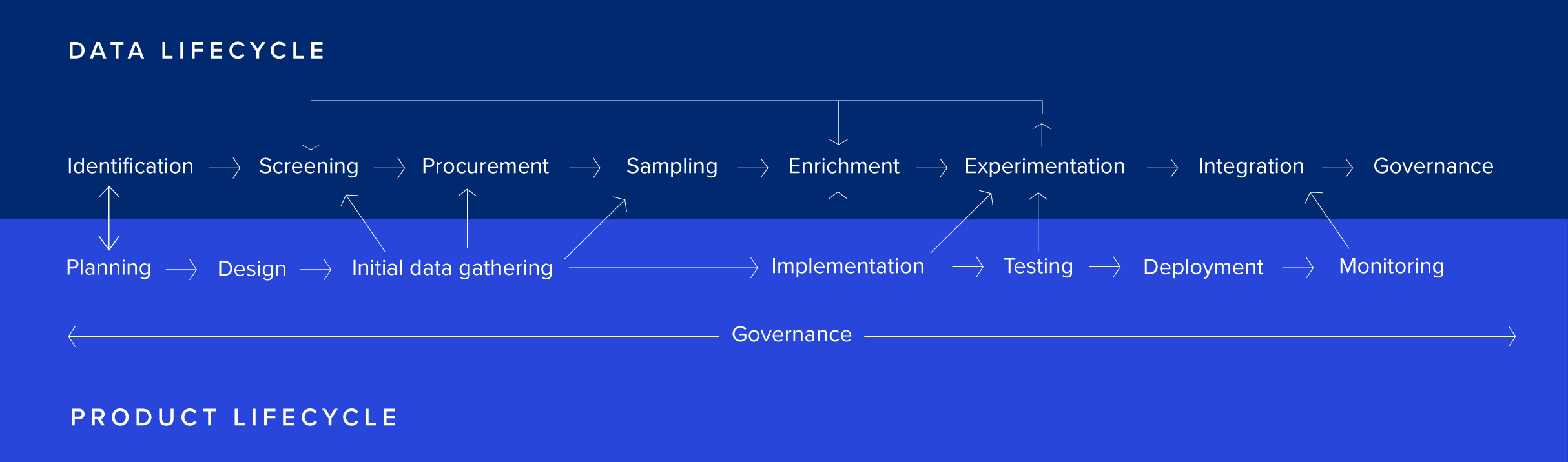
The main stages you’ll want to plan for are:
- Data identification. At this stage, you’ll want to understand what data is potentially available within your system and from third party sources and how they relate to your business use case. Starting out with some idea of each data set’s expected “lift” will provide a key metric to help you understand when you need to abandon the development if expectations are not being met in experimentation.
- Data screening. At this stage, you’ll dig one level deeper to understand important characteristics of the data: How much of it is there? Are there constraints on its use you’ll need to be aware of? What type of metadata is available? Is it available in real-time or periodically?
- Data procurement. At this stage, you’ll want to actually get some data into your environment to work with. This may involve drawing on your own proprietary sources, pulling from publicly available datasets or purchasing data.
- Data sampling. Before diving into modeling, it’s always a good idea to spend some time actually looking at individual data points to build up an intuition for the data set. This can save a lot of time in choosing an appropriate modeling direction and explaining your initial results. It should also reveal whether data enrichment is necessary.
- Data enrichment. To make the data useful, it may need to be enriched by augmenting it with additional features, by adding human annotations or by combining it with other data sets.
- Data experimentation. In this step, your goal is to experiment with different models that make predictions based on the data. You may need to experiment several times and in several different ways before finding something that provides acceptable performance for your use case.
- Data integration. Once you’ve hit on a satisfactory way of using your data, you’ll want to integrate it into a production-ready system. You’ll need to think about how data will enter your system and what feedback loops you want to build around it.
- Data monitoring. Once your product is live, you’ll need to regularly monitor its performance to maintain quality and avoid model drift as data and user needs change over time.
- Data governance. Throughout the process, plan for data governance. You’ll need to think through how data quality, reliability, privacy, security and compliance will be maintained over time, how data will be made accessible and how documentation will be maintained. There are well-known frameworks (such as DCAM and DAMA) you can adopt that will help ensure you are covering the most important areas.

Structuring data sprints
At each of these steps, you’ll want to run data sprints. Using a sprint can make dealing with data less overwhelming, but it’s important to structure each sprint so that it has a positive outcome. For instance, a data experimentation sprint may or may not yield successful results in terms of model outcomes, but if the purpose of the sprint is to answer questions about the data, it’s likelier that you’ll get a sense of forward progress even if your next steps are to plan further experimentation sprints to evaluate other opportunities.
The three components of the data lifecycle that particularly benefit from an agile approach are data identification, data experimentation and governance — but they are also easily underestimated. Here are some examples of questions you might use to structure sprints at each of these stages. Careful identification of questions that you’d like to answer at each stage will help focus your efforts in each sprint, and ensure that each sprint has well-defined stopping criteria set up in advance.
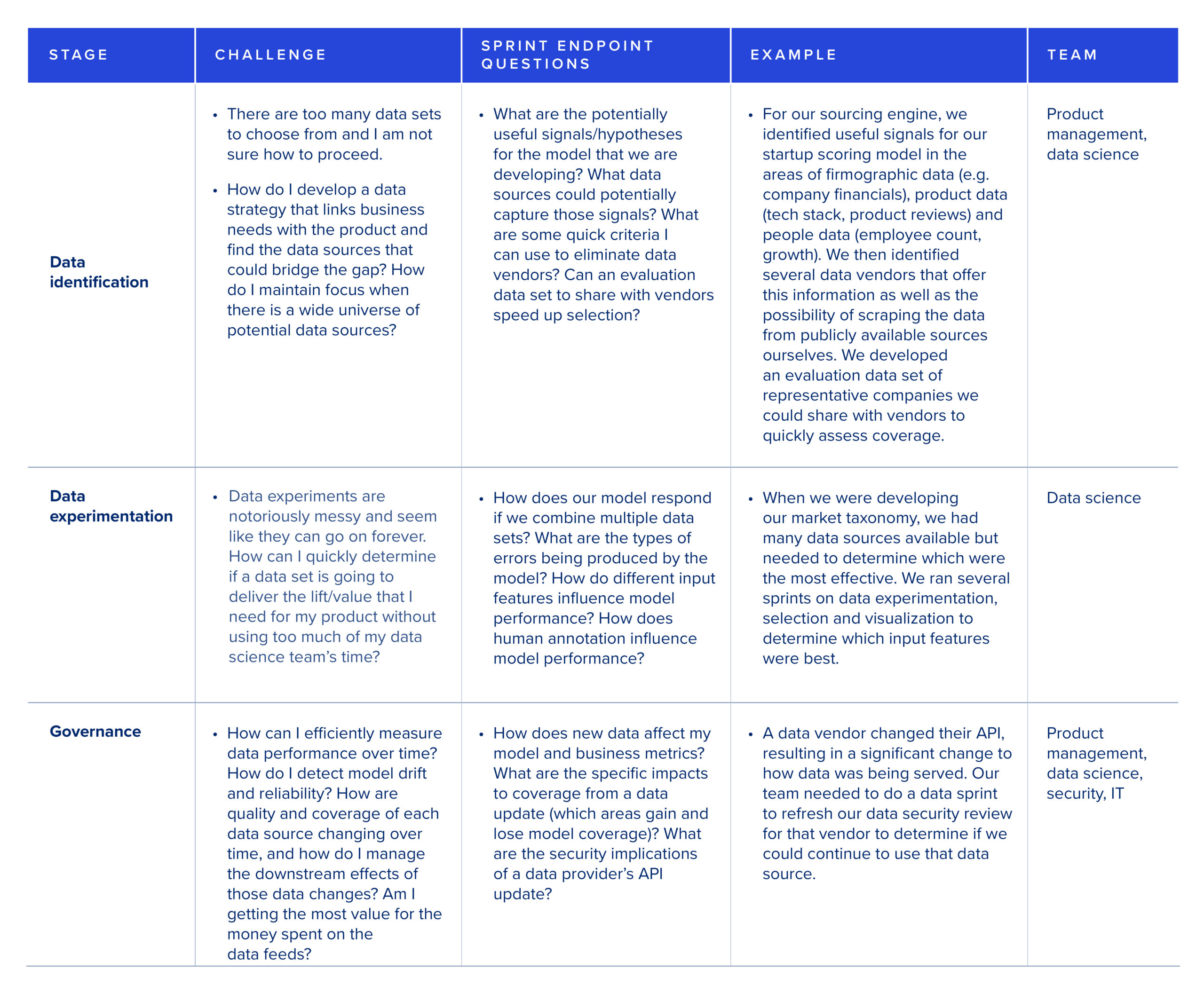
The complexity of using data may seem daunting. A data lifecycle model helps break things down into manageable units that can be more easily mapped to an agile development process. Structuring iterative data sprints with well-defined endpoints will improve your team’s velocity and help you balance customer experience with your team’s time and budget.
This is the fourth in a series on agile AI. If you want to receive the rest to your inbox, sign up for our newsletter here.
Next time, in our Agile Series, I’ll talk about MLOps offerings and tools that can help with the AI product development process.
Part 1: Finding Your Project’s North Star, Part 2: Nurturing your AI Team and Part 3: Experimentation and Effort Allocation
This blog was originally published on our Medium blog.
Read more like this
Why Georgian Invested in Coder
We are excited to announce that Georgian has led Coder’s $35M fundraise…
Why Georgian is Investing in SurrealDB
The proliferation of unstructured data has, in our view, made building modern…
Redefining Legal Impact with the Team at Darrow
When we think about legal tech software, we think about value add…